EntityDetection is a Paper plugin with which you can quickly find chunks with a large amount of Monsters, Animals or even Tile Entities like Hoppers in it.
Very useful if you want to find XP-Farms that accumulate a large amount of mobs or that one infinite chicken or villager breeder that brings your server to its knees!
Installation
Download the latest version of the EntityDetection plugin:
Place the downloaded .jar file into the plugins directory of your Paper server.
Restart the server to enable the plugin.
Dependencies
This plugin does not require any other plugin to run, but it requires Paper to be used as the server software and can optionally integrate with WorldGuard for region-based entity detection.
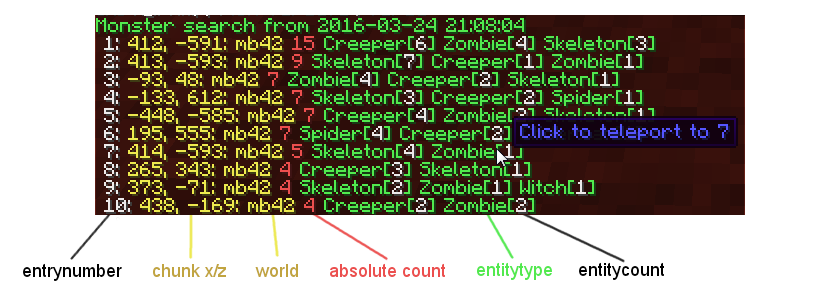
The main plugin command. Start a search for chunks with lots of entities in it. Without any type it searches for Monsters but you can also search for a specific type of entities (take a look at the different types below) or for single entity types. With version 1.1 you can also search for Hopper and other blockstates! You can also combine different types by just inputting them after each other separated by a space. When the search is finished you will get a list for all chunks sorted by their entity count.
/detect search --regions [<type>]
List results based on WorldGuard regions instead of chunks
/detect list [<page> [monster|passive|misc|block|tile|all|<type>]]
List more pages of a previous search result. You can specify a type to see the last search of a specific type.
/detect stop
Stops the currently running search.
/detect tp <#result>
Teleport to a specific entry number from a search. (You can also directly click on the entry line to teleport to it!)
Search Types:
Monster
All the monsters and slimes
Passive
All the animals, NPCs and golems as well as ambient and water mobs
Misc
Everything that is not a real mob: fireworks, boats, minecarts, projectiles, dropped items, ender signals and lightning strikes.
Block (More like pseudo-block but that’s too long)
Entities that behave more like blocks than entities: armor stands, ender crystals, paintings, item frames and falling blocks.
Entity
Search for all the entities, no matter what type they are
Tile
Search for all tile entities, no matter what type they are
All
Search for everything entities and tile entities/blockstates, no matter what type they are
The categories aren’t enough? Then you can search for specific tile entities directly! This is done by either inputting the class name of their block state (which is case sensitive) or the Material name!
You can also search for the specific Bukkit entity type! Every single one is supported and can be combined with the other search types.
If you have ideas how one of the types could be improved or for a new one just respond to the discussion thread or directly submit a pull request for a modification of the SearchType enum!
Examples
To search for all monsters: /detect search monster
To list the results of the last search: /detect list
To teleport to the first result: /detect tp 1
Permissions
entitydetection.command
Allows the player to use the /detect command.
Default: op
entitydetection.command.search
Allows the player to use the /detect search command.
Default: op
entitydetection.command.list
Allows the player to use the /detect list command.
Default: op
entitydetection.command.stop
Allows the player to use the /detect stop command.
Default: op
entitydetection.command.tp
Allows the player to use the /detect tp command.
Default: op
Configuration
The plugin supports multiple languages. You can set the default language via the de.themoep.entitydetection.default-language system property and create your own language files in the languages folder. The default language is English (en).
Contributing
Contributions are welcome! If you find any bugs or have feature requests, please open an issue on the GitHub repository.
License
This project is licensed under the Mozilla Public License version 2.0. See the LICENSE file for details.
this package contains a nc2ts_by_shp.py script. A command line tool that can be used to quickly extract
reduced(min/max/average/weighted average) time-series form netcdf file with shapefile
# with 3d array [data/sample_2.nc] generel case
$ nc2ts_by_shp.py -nc=sample_2.nc -nci='Y=lat;X=lon;T=time;V=tmin;' -s=shape_esri.zip \
-sp='ADM2_EN;ADM3_EN' -r=avg -o=test2.csv
# with 4d array [data/sample_1.nc]
$ nc2ts_by_shp.py -nc=sample_1.nc -nci='Y=lat;X=lon;T=time;V=temperature;slicer=[:,0,:,:]' -sf=shape_esri.zip \
-sfp='ADM2_EN;ADM3_EN' -r=wavg -o=test1.csv
Options:
-nc = netcdf file
-nci = netcdf variable and dimension information
available options:
X = x dimension variable name,
Y = y dimension variable name,
T = time dimension variable name,
V = variable name,
slicer = slicing index for obtaining 3d array [optional]
note: `slicer` is required if variable has more than three dimension
-sf = shape file ( can be zipped shapefile, shapefile or geojson )
-sfp = shapefile properties
only required when shapefile contains multiple records
-r = reducer, default is average
Available options: min,max,avg,wavg
-o = output file name
Causes of Erroneous output
- when shapefile and netcdf file have different projection
- shapefile dosen't fully reside within netcdf bounds
Creditcoin is a network that enables cross-blockchain credit transaction and credit history building. Creditcoin uses blockchain technology to ensure the objectivity of its credit transaction history: each transaction on the network is distributed and verified by the network.
The Creditcoin protocol was created by Gluwa. Gluwa Creditcoin is the official implementation of the Creditcoin protocol by Gluwa.
Licenses of dependencies distributed with this repository are provided under the \DependencyLicense directory.
Development Process
The master branch is regularly built and tested, but it is not guaranteed to be completely stable.
Tags are created regularly from release branches to indicate new official, stable release versions of Gluwa Creditcoin.
Prerequisite for Windows
Boost 1.67.0 source
Place the source of boost 1.67.0 to C:\local\boost_1_67_0.
If you would like to use your own directory, you can change the setting in the project properties under
C/C++ => Generals => Additional Include Directories.
Static Library
Place the following .lib into \SDK\lib\Debug folder.
Boost 1.67.0:
Download pre-built binaries for boost 1.67.0
Take the following the .libs from the lib64-msvc-14.1 folder
Service to import data from various sources (e.g. PDF, images, Microsoft Office, HTML) and index it in AI Search. Increases data relevance and reduces final size by 90%+. Useful for RAG scenarios with LLM. Hosted in Azure with serverless architecture.
Overview
In a real-world scenario, with a public corpus of 15M characters (222 PDF, 7.330 pages), 2.940 facts were generated (8.41 MB indexed). That’s a 93% reduction in document amount compared to the chunck method (48.111 chuncks, 300 characters each).
It includes principles taken from research papers:
This project is a proof of concept. It is not intended to be used in production. This demonstrates how can be combined Azure serverless technologies and LLM to a high quality search engine for RAG scenarios.
Cost anything when not used thanks to serverless architecture
Data can be searched with semantic queries using AI Search
Deduplicate content
Extract text from PDF, images, Microsoft Office, HTML
Garbage data detection
Index files from more than 1000 pages
Remove redundant and irrelevant content by synthesis data generation
Format support
Document extraction is based on Azure Document Intelligence, specifically on the prebuilt-layout model. It supports popular formats.
Some formats are first converted to PDF with MuPDF to ensure compatibility with Document Intelligence.
Important
Formats not listed there are treated as binary and decoded with UTF-8 encoding.
{
"created_at": "2024-06-08T19:17:51.229972Z",
"document_content": "Code des assurances\n===\n\ndroit. org Institut Français d'Information Juridique\n\nDernière modification: 2024-01-01 Edition : 2024-01-19 2347 articles avec 5806 liens 57 références externes\n\nCe code ne contient que du droit positif français, les articles et éléments abrogés ne sont pas inclus. Il est recalculé au fur et à mesure des mises à jour. Pensez à actualiser votre copie régulièrement à partir de codes.droit.org.\n\nCes codes ont pour objectif de démontrer l'utilité de l'ouverture des données publiques juridiques tant législatives que jurisprudentielles. Il s'y ajoute une promotion du mouvement Open Science Juridique avec une incitation au dépôt du texte intégral en accès ouvert des articles de doctrine venant du monde professionnel (Grande Bibliothèque du Droit) et universitaire (HAL-CNRS).\n\nTraitements effectués à partir des données issues des APIs Legifrance et Judilibre. droit.org remercie les acteurs du Web qui autorisent des liens vers leur production : Dictionnaire du Droit Privé (réalisé par MM. Serge Braudo et Alexis Baumann), le Conseil constitutionnel, l'Assemblée Nationale, et le Sénat. [...]",
"file_path": "raw/code_des_assurances_2024_1.pdf",
"format": "markdown",
"langs": ["es", "la", "fr", "ja", "en", "it", "pt", "no"],
"title": "Code des assurances\n==="
}
Second, document is paged, and each page is synthesized to keep track of the context during all steps:
{
"synthesis": "The \"Code des assurances\" is structured into several legislative parts and chapters, each dealing with various aspects of insurance law and regulations in France. It covers a wide range of insurance-related subjects including the operation of insurance and reinsurance contracts, the requirements for companies, the obligations of insurers and insured, and the legal framework governing insurance practices. The document includes regulations about the constitution and operation of insurance entities, rules for granting administrative approvals, conditions for opening branches and operating under free provision of services, among others.\n\nSpecifically, it addresses the following:\n1. The legislative basis for insurance contracts.\n2. Detailed provisions on maritime, aerial, and space liability insurances.\n3. Obligations for reporting and transparency in insurance practices.\n4. Rules for life insurance and capitalizations applicable in specific French regions and territories.\n5. Provisions for mandatory insurance types, like vehicle insurance, residence insurance, and insurance of construction work.\n6. Specific rules and exceptions for departments like Bas-Rhin, Haut-Rhin, and Moselle and applicability in French overseas territories. [...]"
}
Third, multiple facts (=Q&A pairs) are generated, and those are critiqued to keep only the most relevant ones:
{
"facts": [
{
"answer": "The 'Code des assurances' only contains active French law; abrogated articles and elements are not included.",
"context": "This exclusion ensures that the code remains up-to-date and relevant, reflecting the current legal landscape without outdated information.",
"question": "What elements are excluded from the 'Code des assurances'?"
},
{
"answer": "Insurance can be contracted for the policyholder, for another specified person, or for whomever it may concern.",
"context": "This flexibility allows insurance policies to be tailored to various scenarios, ensuring broad applicability and relevance to different stakeholders.",
"question": "For whom can insurance be contracted according to the document?"
}
]
}
Finally, facts are individually indexed in AI Search:
{
"answer": "The 'Code des assurances' only contains active French law; abrogated articles and elements are not included.",
"context": "This exclusion ensures that the code remains up-to-date and relevant, reflecting the current legal landscape without outdated information.",
"document_synthesis": "The \"Code des assurances\" is structured into several legislative parts and chapters, each dealing with various aspects of insurance law and regulations in France. It covers a wide range of insurance-related subjects including the operation of insurance and reinsurance contracts, the requirements for companies, the obligations of insurers and insured, and the legal framework governing insurance practices. The document includes regulations about the constitution and operation of insurance entities, rules for granting administrative approvals, conditions for opening branches and operating under free provision of services, among others.\n\nSpecifically, it addresses the following:\n1. The legislative basis for insurance contracts.\n2. Detailed provisions on maritime, aerial, and space liability insurances.\n3. Obligations for reporting and transparency in insurance practices.\n4. Rules for life insurance and capitalizations applicable in specific French regions and territories.\n5. Provisions for mandatory insurance types, like vehicle insurance, residence insurance, and insurance of construction work.\n6. Specific rules and exceptions for departments like Bas-Rhin, Haut-Rhin, and Moselle and applicability in French overseas territories. [...]",
"file_path": "raw/code_des_assurances_2024_1.pdf",
"id": "93e5846ba121abf6ea3328a7ff5a96b60ab97ce2016166ac0384f2e61a963d6d",
"question": "What elements are excluded from the 'Code des assurances'?"
}
High level architecture
---
title: High level process
---
graph LR
importer["Importer"]
openai_ada["Ada\n(OpenAI)"]
search_index["Index\n(AI Search)"]
storage[("Blob\n(Storage Account)")]
importer -- Pull from --> storage
importer -- Push to --> search_index
search_index -. Generate embeddings .-> openai_ada
Loading
Component level architecture
---
title: Importer component diagram (C4 model)
---
graph LR
openai_ada["Ada\n(OpenAI)"]
search_index["Index\n(AI Search)"]
storage[("Blob\n(Storage Account)")]
subgraph importer["Importer"]
document["Document extraction\n(Document Intelligence)"]
openai_gpt["GPT-4o\n(OpenAI)"]
func_chunck["Chunck\n(Function App)"]
func_critic["Critic\n(Function App)"]
func_extract["Extracted\n(Function App)"]
func_fact["Fact\n(Function App)"]
func_index["Index\n(Function App)"]
func_page["Page\n(Function App)"]
func_sanitize["Sanitize\n(Function App)"]
func_synthesis["Synthetisis\n(Function App)"]
end
func_sanitize -- Pull from --> storage
func_sanitize -- Convert and linearize --> func_sanitize
func_sanitize -- Push to --> func_extract
func_extract -- Ask for extraction --> document
func_extract -. Poll for result .-> document
func_extract -- Push to --> func_chunck
func_chunck -- Split into large parts --> func_chunck
func_chunck -- Push to --> func_synthesis
func_synthesis -- Create a chunck synthesis --> openai_gpt
func_synthesis -- Push to --> func_page
func_page -- Split into small parts --> func_page
func_page -- Clean and filter repetitive content --> func_page
func_page -- Push to --> func_fact
func_fact -- Create Q/A pairs --> openai_gpt
func_fact -- Push to --> func_critic
func_critic -- Push to --> func_index
func_critic -- Create a score for each fact --> openai_gpt
func_critic -- Filter out irrelevant facts --> func_critic
func_index -- Generate reproductible IDs --> func_index
func_index -- Push to --> search_index
search_index -. Generate embeddings .-> openai_ada
Loading
Usage cost
From experiments, the cost of indexing a document is around 29.15€ per 1k pages. Here is a detailed breakdown:
Scenario:
7.330 pages (15M characters)
222 PDF (550.50 MB)
French (90%) and English (10%)
Outcome:
2.940 facts generated
8.41 MB indexed on AI Search
Cost:
Service
Usage
Cost (abs)
Cost (per 1k pages)
Azure AI Search
Billed per hour
N/A
N/A
Azure Blob Storage
N/A
N/A
N/A
Azure Document Intelligence
7.330 pages
67,79€
9.25€
Azure Functions
N/A
N/A
N/A
Azure OpenAI GPT-4o (in)
23.79M tokens
111,81€
15.25€
Azure OpenAI GPT-4o (out)
2.45M tokens
34,06€
4.65€
Total
213,66€
29.15€
Local installation
Some prerequisites are needed to deploy the solution.
To override a specific configuration value, you can also use environment variables. For example, to override the llm.fast.azure_openai.endpoint value, you can use the LLM__FAST__AZURE_OPENAI__ENDPOINT variable:
Service to import data from various sources (e.g. PDF, images, Microsoft Office, HTML) and index it in AI Search. Increases data relevance and reduces final size by 90%+. Useful for RAG scenarios with LLM. Hosted in Azure with serverless architecture.
Overview
In a real-world scenario, with a public corpus of 15M characters (222 PDF, 7.330 pages), 2.940 facts were generated (8.41 MB indexed). That’s a 93% reduction in document amount compared to the chunck method (48.111 chuncks, 300 characters each).
It includes principles taken from research papers:
This project is a proof of concept. It is not intended to be used in production. This demonstrates how can be combined Azure serverless technologies and LLM to a high quality search engine for RAG scenarios.
Cost anything when not used thanks to serverless architecture
Data can be searched with semantic queries using AI Search
Deduplicate content
Extract text from PDF, images, Microsoft Office, HTML
Garbage data detection
Index files from more than 1000 pages
Remove redundant and irrelevant content by synthesis data generation
Format support
Document extraction is based on Azure Document Intelligence, specifically on the prebuilt-layout model. It supports popular formats.
Some formats are first converted to PDF with MuPDF to ensure compatibility with Document Intelligence.
Important
Formats not listed there are treated as binary and decoded with UTF-8 encoding.
{
"created_at": "2024-06-08T19:17:51.229972Z",
"document_content": "Code des assurances\n===\n\ndroit. org Institut Français d'Information Juridique\n\nDernière modification: 2024-01-01 Edition : 2024-01-19 2347 articles avec 5806 liens 57 références externes\n\nCe code ne contient que du droit positif français, les articles et éléments abrogés ne sont pas inclus. Il est recalculé au fur et à mesure des mises à jour. Pensez à actualiser votre copie régulièrement à partir de codes.droit.org.\n\nCes codes ont pour objectif de démontrer l'utilité de l'ouverture des données publiques juridiques tant législatives que jurisprudentielles. Il s'y ajoute une promotion du mouvement Open Science Juridique avec une incitation au dépôt du texte intégral en accès ouvert des articles de doctrine venant du monde professionnel (Grande Bibliothèque du Droit) et universitaire (HAL-CNRS).\n\nTraitements effectués à partir des données issues des APIs Legifrance et Judilibre. droit.org remercie les acteurs du Web qui autorisent des liens vers leur production : Dictionnaire du Droit Privé (réalisé par MM. Serge Braudo et Alexis Baumann), le Conseil constitutionnel, l'Assemblée Nationale, et le Sénat. [...]",
"file_path": "raw/code_des_assurances_2024_1.pdf",
"format": "markdown",
"langs": ["es", "la", "fr", "ja", "en", "it", "pt", "no"],
"title": "Code des assurances\n==="
}
Second, document is paged, and each page is synthesized to keep track of the context during all steps:
{
"synthesis": "The \"Code des assurances\" is structured into several legislative parts and chapters, each dealing with various aspects of insurance law and regulations in France. It covers a wide range of insurance-related subjects including the operation of insurance and reinsurance contracts, the requirements for companies, the obligations of insurers and insured, and the legal framework governing insurance practices. The document includes regulations about the constitution and operation of insurance entities, rules for granting administrative approvals, conditions for opening branches and operating under free provision of services, among others.\n\nSpecifically, it addresses the following:\n1. The legislative basis for insurance contracts.\n2. Detailed provisions on maritime, aerial, and space liability insurances.\n3. Obligations for reporting and transparency in insurance practices.\n4. Rules for life insurance and capitalizations applicable in specific French regions and territories.\n5. Provisions for mandatory insurance types, like vehicle insurance, residence insurance, and insurance of construction work.\n6. Specific rules and exceptions for departments like Bas-Rhin, Haut-Rhin, and Moselle and applicability in French overseas territories. [...]"
}
Third, multiple facts (=Q&A pairs) are generated, and those are critiqued to keep only the most relevant ones:
{
"facts": [
{
"answer": "The 'Code des assurances' only contains active French law; abrogated articles and elements are not included.",
"context": "This exclusion ensures that the code remains up-to-date and relevant, reflecting the current legal landscape without outdated information.",
"question": "What elements are excluded from the 'Code des assurances'?"
},
{
"answer": "Insurance can be contracted for the policyholder, for another specified person, or for whomever it may concern.",
"context": "This flexibility allows insurance policies to be tailored to various scenarios, ensuring broad applicability and relevance to different stakeholders.",
"question": "For whom can insurance be contracted according to the document?"
}
]
}
Finally, facts are individually indexed in AI Search:
{
"answer": "The 'Code des assurances' only contains active French law; abrogated articles and elements are not included.",
"context": "This exclusion ensures that the code remains up-to-date and relevant, reflecting the current legal landscape without outdated information.",
"document_synthesis": "The \"Code des assurances\" is structured into several legislative parts and chapters, each dealing with various aspects of insurance law and regulations in France. It covers a wide range of insurance-related subjects including the operation of insurance and reinsurance contracts, the requirements for companies, the obligations of insurers and insured, and the legal framework governing insurance practices. The document includes regulations about the constitution and operation of insurance entities, rules for granting administrative approvals, conditions for opening branches and operating under free provision of services, among others.\n\nSpecifically, it addresses the following:\n1. The legislative basis for insurance contracts.\n2. Detailed provisions on maritime, aerial, and space liability insurances.\n3. Obligations for reporting and transparency in insurance practices.\n4. Rules for life insurance and capitalizations applicable in specific French regions and territories.\n5. Provisions for mandatory insurance types, like vehicle insurance, residence insurance, and insurance of construction work.\n6. Specific rules and exceptions for departments like Bas-Rhin, Haut-Rhin, and Moselle and applicability in French overseas territories. [...]",
"file_path": "raw/code_des_assurances_2024_1.pdf",
"id": "93e5846ba121abf6ea3328a7ff5a96b60ab97ce2016166ac0384f2e61a963d6d",
"question": "What elements are excluded from the 'Code des assurances'?"
}
High level architecture
---
title: High level process
---
graph LR
importer["Importer"]
openai_ada["Ada\n(OpenAI)"]
search_index["Index\n(AI Search)"]
storage[("Blob\n(Storage Account)")]
importer -- Pull from --> storage
importer -- Push to --> search_index
search_index -. Generate embeddings .-> openai_ada
Loading
Component level architecture
---
title: Importer component diagram (C4 model)
---
graph LR
openai_ada["Ada\n(OpenAI)"]
search_index["Index\n(AI Search)"]
storage[("Blob\n(Storage Account)")]
subgraph importer["Importer"]
document["Document extraction\n(Document Intelligence)"]
openai_gpt["GPT-4o\n(OpenAI)"]
func_chunck["Chunck\n(Function App)"]
func_critic["Critic\n(Function App)"]
func_extract["Extracted\n(Function App)"]
func_fact["Fact\n(Function App)"]
func_index["Index\n(Function App)"]
func_page["Page\n(Function App)"]
func_sanitize["Sanitize\n(Function App)"]
func_synthesis["Synthetisis\n(Function App)"]
end
func_sanitize -- Pull from --> storage
func_sanitize -- Convert and linearize --> func_sanitize
func_sanitize -- Push to --> func_extract
func_extract -- Ask for extraction --> document
func_extract -. Poll for result .-> document
func_extract -- Push to --> func_chunck
func_chunck -- Split into large parts --> func_chunck
func_chunck -- Push to --> func_synthesis
func_synthesis -- Create a chunck synthesis --> openai_gpt
func_synthesis -- Push to --> func_page
func_page -- Split into small parts --> func_page
func_page -- Clean and filter repetitive content --> func_page
func_page -- Push to --> func_fact
func_fact -- Create Q/A pairs --> openai_gpt
func_fact -- Push to --> func_critic
func_critic -- Push to --> func_index
func_critic -- Create a score for each fact --> openai_gpt
func_critic -- Filter out irrelevant facts --> func_critic
func_index -- Generate reproductible IDs --> func_index
func_index -- Push to --> search_index
search_index -. Generate embeddings .-> openai_ada
Loading
Usage cost
From experiments, the cost of indexing a document is around 29.15€ per 1k pages. Here is a detailed breakdown:
Scenario:
7.330 pages (15M characters)
222 PDF (550.50 MB)
French (90%) and English (10%)
Outcome:
2.940 facts generated
8.41 MB indexed on AI Search
Cost:
Service
Usage
Cost (abs)
Cost (per 1k pages)
Azure AI Search
Billed per hour
N/A
N/A
Azure Blob Storage
N/A
N/A
N/A
Azure Document Intelligence
7.330 pages
67,79€
9.25€
Azure Functions
N/A
N/A
N/A
Azure OpenAI GPT-4o (in)
23.79M tokens
111,81€
15.25€
Azure OpenAI GPT-4o (out)
2.45M tokens
34,06€
4.65€
Total
213,66€
29.15€
Local installation
Some prerequisites are needed to deploy the solution.
To override a specific configuration value, you can also use environment variables. For example, to override the llm.fast.azure_openai.endpoint value, you can use the LLM__FAST__AZURE_OPENAI__ENDPOINT variable:
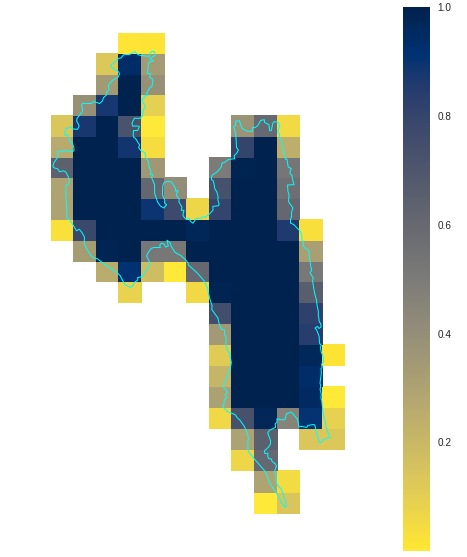
Convert a GeoJSON feature to a set of hexagons. Only hexagons whose centers
fall within the feature will be included. Note that conversion from GeoJSON
is lossy; the resulting hexagon set only approximately describes the original
shape, at a level of precision determined by the hexagon resolution.
If the polygon is small in comparison with the chosen resolution, there may be
no cell whose center lies within it, resulting in an empty set. To fall back
to a single H3 cell representing the centroid of the polygon in this case, use
the ensureOutput option.
Kind: static method of geojson2h3 Returns: Array.<String> – H3 indexes
Param
Type
Description
feature
Object
Input GeoJSON: type must be either Feature or FeatureCollection, and geometry type must be either Polygon or MultiPolygon
resolution
Number
Resolution of hexagons, between 0 and 15
[options]
Object
Options
[options.ensureOutput]
Boolean
Whether to ensure that at least one cell is returned in the set
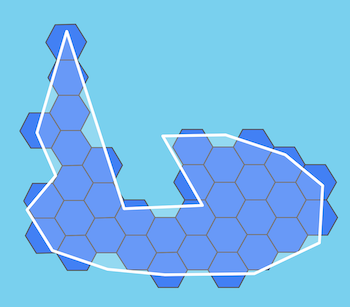
Convert a set of hexagons to a GeoJSON Feature with the set outline(s). The
feature’s geometry type will be either Polygon or MultiPolygon depending on
the number of outlines required for the set.
Optional function returning properties for a hexagon: f(h3Index) => Object
Development
The geojson2h3 library uses yarn as the preferred package manager. To install the dev dependencies, just run:
yarn
To run the tests in both native ES6 (requires Node >= 6) and transpiled ES5:
yarn test
To format the code:
yarn prettier
To rebuild the API documentation in the README file:
yarn build-docs
Contributing
Pull requests and Github issues are welcome. Please include tests for new work, and keep the library test coverage at 100%. Before we can merge your changes, you must agree to the Uber Contributor License Agreement.
Convert a GeoJSON feature to a set of hexagons. Only hexagons whose centers
fall within the feature will be included. Note that conversion from GeoJSON
is lossy; the resulting hexagon set only approximately describes the original
shape, at a level of precision determined by the hexagon resolution.
If the polygon is small in comparison with the chosen resolution, there may be
no cell whose center lies within it, resulting in an empty set. To fall back
to a single H3 cell representing the centroid of the polygon in this case, use
the ensureOutput option.
Kind: static method of geojson2h3 Returns: Array.<String> – H3 indexes
Param
Type
Description
feature
Object
Input GeoJSON: type must be either Feature or FeatureCollection, and geometry type must be either Polygon or MultiPolygon
resolution
Number
Resolution of hexagons, between 0 and 15
[options]
Object
Options
[options.ensureOutput]
Boolean
Whether to ensure that at least one cell is returned in the set
Convert a set of hexagons to a GeoJSON Feature with the set outline(s). The
feature’s geometry type will be either Polygon or MultiPolygon depending on
the number of outlines required for the set.
Optional function returning properties for a hexagon: f(h3Index) => Object
Development
The geojson2h3 library uses yarn as the preferred package manager. To install the dev dependencies, just run:
yarn
To run the tests in both native ES6 (requires Node >= 6) and transpiled ES5:
yarn test
To format the code:
yarn prettier
To rebuild the API documentation in the README file:
yarn build-docs
Contributing
Pull requests and Github issues are welcome. Please include tests for new work, and keep the library test coverage at 100%. Before we can merge your changes, you must agree to the Uber Contributor License Agreement.


 https://github.com/Minebench/EntityDetection
https://github.com/Minebench/EntityDetection